
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 통화정책파급경로
- 코딩테스트
- montecarlo
- 증권투자권유자문인력
- python
- potatoeseater
- 집중하는법
- ReinforcementLearning
- 도둑맞은집중력
- 독서모임
- 블라인드테스트
- SQL
- 독후감
- 카카오
- RL
- 요한하리
- Nas
- 프로그래머스
- 재무엑셀
- pandas
- 재무제표
- agviewer
- 주식
- ldbc
- 책읽는케이크
- 파이썬
- 인도가격
- 파생상품평가모형
- dataanalysis
- 통화주의학파
- Today
- Total
이것저것 담는 블로그
Neural Architecture Search : A Survey 논문 요약 및 리뷰 - Part 2 본문
Neural Architecture Search : A Survey 논문 요약 및 리뷰 - Part 2
버즈와우디 2021. 8. 19. 00:34이전 Part 1에 이어서 NAS에 대해 더 알아보자.
Neural Architecture Search : A Survey 논문 요약 및 리뷰 - Part 1
이 글은 Neural Architecture Search : A Survey, Thomas Elsken et al., 2019 논문을 요약하고 리뷰하는 첫번째 포스트이다. 논문 원본은 아래에서 볼 수 있다. Neural Architecture Search: A Survey Deep Learn..
miidsummer.tistory.com
3. Search Strategy
인공신경망을 탐색하기 위한 전략으로는 random search, Bayesian optimization, evolutionary methods, reinforcement learning(RL), gradient-based method 등이 활용되어 왔다.
그 중 evolutionary algorithm의 경우는 1994년부터 꽤 오래전부터 활용되어오던 방법이다.
Bayesian optimization은 2013년에 vision 아키텍처를 이끌면서 큰 성공을 이루었고 data augmentation (데이터 증강) 없이 사람 전문가보다 뛰어난 CIFAR-10 데이터셋의 성능을 보였다.
reinforcement learning (강화학습)을 활용해 CIFAR-10 과 Penn Treebank 학습 성능을 높인 사례가 발표되며 본격적으로 NAS는 주요 학문으로 자리잡았다.
NAS를 강화학습 문제의 일종으로 보면, 인공신경망을 생성하는 것이 에이전트의 행동이 되고 학습되지 않은 데이터에 대한 추론 성능이 에이전트의 보상이 된다.
에이전트의 정책과 최적화 방법에 따라 강화학습이 다르게 적용되었는데, 대표적인 예로 인공신경망을 차례대로 인코딩한 string 값을 차례대로 샘플링하는 RNN 정책이 있는데 (Zoph and Le (2017)) REINFORCE policy gradient 알고리즘으로 네트워크를 초기 학습시켰다.
이후 연구에서는 PPO(Proximal Policy Optimization)을 활용했다.
Bakers et al. (2018) 연구진은 레이어의 타입과 그에 상응하는 hyperparameter를 순차적으로 선택하는 정책을 Q러닝을 활용해 학습했다.
하지만 위의 문제정의에서는 보상에 discount를 적용하지 않아서 마지막에 선택된 행동에 대한 보상으로만 학습하게 된다.
따라서 강화학습의 환경과 상호작용이 없기 때문에 RL 문제라기 보다는 stateless multi-armed bandit 문제로 축소시킬 수 있다.
Cai et al. (2018a) 논문에서는 bi-directional LSTM을 써서 가변적인 길이를 가지는 네트워크를 고정적인 길이를 가지도록 인코딩하였고, 샘플링된 행동 중에서 actor 네트워크가 선택하는 방식으로 순차적으로 NAS를 구현했다.
인공신경망과 그 가중치를 최적화하기 위해 예전부터 genetic algorithm (유전 알고리즘)이 많이 활용되었으나 근래 들어 SGD 기반의 weight optimization (가중치 최적화) 방법을 많이 활용한다.
이러한 방법들을 neuro-evolutionary approach 라고 한다.
최근에는 가중치 최적화는 gradient based method를 많이 활용하고 인공신경망 자체를 최적화 하는 것은 evolutionary algorithm을 많이 활용한다.
어느정도 학습이 된 모델 집합 중에서 부모가 될 모델을 골라서 mutations(돌연변이)에 해당하는 자녀 모델을 만든 후 적합하다고 판단되면 모델 집합 또는 populations에 넣는 방식이다.
여기서 mutations 를 생성하는 방법으로는 레이어를 추가/삭제하거나, skip connection을 추가하거나, 학습 파라미터를 바꾸는 것 등이 있다.
아래와 같이 다양하게 적용할 수 있다.
|
Bayesian Optimization 기법은 hyperparameter를 최적화할 때 많이 사용되었었지만, BO toolboxes 가 저차원 문제에 대해서만 최적화를 제공하는 바람에 NAS에서는 많이 사용되지는 않았었다.
하지만 아래 연구들이 진행되면서 evolutional algorithm보다 더 뛰어난 성능을 보일 수 있는 것이 밝혀졌다.
초기엔 kernel functions를 활용하거나 tree-based model, random forest 등과 BO를 같이 활용한 연구들이 진행되었다.
특히 탐색공간을 tree 구조로 구성하고 Monte Carlo Tree Search를 활용한 연구, hill climbing 알고리즘으로 그리디하게 탐색공간을 탐험하여 architecuture를 찾는 연구 등도 수행되었다.
앞서 언급된 방법들은 discrete search space (이산 탐색 공간)을 가정했다면 Liu et al. (2019b)는 continuous relaxation 기법을 활용하여 convex combination을 수식화했다.
보통의 이산 탐색 공간에서라면 하나의 operation이 convolution이나 pooling 둘 중 하나를 고르는 것이었다면 이 논문에서는 여러 operation 의 가중합을 계산하는 독특한 방식을 선택했다.
인풋 레이어가 x, 아웃풋 레이어가 y이고 operation 집합이 O, 요소가 o_i 일 때, 아래와 같이 계산할 수 있다.
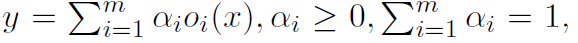
이로써 network weights와 architecture를 모두 최적화했는데, 그 방법은 weights에 대해서는 학습 데이터에 그리고 architecture parameter (위에서의 알파같은) 검증 데이터에 gradient descent steps를 번갈아가며 수행하는 것이다.
결과적으로 전체 레이어에 대해 아래처럼 최대값을 가지는 알파의 operation을 선택하여 discrete architecture를 얻을 수 있다.
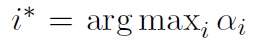
'IT > Machine Learning' 카테고리의 다른 글
| 머신러닝 시그니처 프로젝트 1 (0) | 2024.10.20 |
|---|---|
| bandits 알고리즘의 이해 및 강화학습과의 차이 (0) | 2022.09.19 |
| Neural Architecture Search : A Survey 논문 요약 및 리뷰 - Part 1 (0) | 2021.08.02 |
